Über einige bekannte und weniger bekannte statistische Fallen, in die man beim Factor Investing nicht hineintreten sollte, weil sonst Fabelwesen entstehen: p-Hacking, Overfitting und Factor Mirage.
Ein Kinderlieder-Klassiker heißt: „Die Wissenschaft hat festgestellt, festgestellt, festgestellt, dass …“ In freieren Versionen improvisieren Kinder mit höchster Lust reinen Nonsens – oder was sie dafür halten. Der „traumatische“ Nebeneffekt dieser anarchischen Grundübung: Man bekommt das Lied nie mehr aus den Ohren. So geht es jedenfalls dem Verfasser. Denn der heitere Glaubenskiller erklingt immer dann, wenn Medien berichten, „die Wissenschaft hat festgestellt, dass …“. Aber für diesen inneren Evergreen gibt es häufig gute Gründe.
Im Jahr 2011 veröffentlichte der renommierte Sozialpsychologe Daryl J. Bem im angesehenen Journal of Personality and Social Psychology einen potentiell bahnbrechenden Artikel (Kurztitel „Feeling the Future“). Er wies auf Basis verschiedener Laborexperimente – bei p-Werten unter Signifikanzniveaus zwischen 1 und 5 Prozent – nach, dass Hellseherei (Präkognition) empirisch nachgewiesen werden könne. Ein höchst interessantes Ergebnis gerade auch für Vermögensverwalter. Der Wermutstropfen: Das Ergebnis konnte nicht repliziert werden. In der Folge rückte das sogenannten Replikationsproblem erstmals in die breitere Öffentlichkeit.
Der eigentliche Paukenschlag war bereits im Jahr 2005 erfolgt, wenngleich zunächst nur für das Fachpublikum. In diesem Jahr veröffentlichte John Ioannidis die nun wirklich bahnbrechende Studie „Why Most Published Research Findings Are False“ im Fachjournal PLOS Medicine. Damit eröffnete Ioannidis eine Diskussion, die seither viele akademische Fachbereiche unter dem Begriff „Replikationskrise“ erfasst hat: Wissenschaftlich korrekt erscheinende Ergebnisse von Studien, die in Fachzeitschriften veröffentlicht worden sind, konnten von Kollegen nicht repliziert werden, ganz platt gesagt: sie waren falsch.
Auch Factor-Investing ist in dieser Hinsicht sehr gefährdet. Zwischenzeitlich haben Forscher in wissenschaftlich korrekt erscheinender Form hunderte von Faktoren identifiziert. Cochrane prägte hierfür den Begriff „Faktorzoo“. 2020 untersuchten Kewei Hou, Chen Xue und Lu Zhang 452 Anomalieindikatoren im Finanzbereich. Das Ergebnis: die meisten ließen sich nicht replizieren und sind damit heiße Anwärter für das Gehege der Fabelfaktoren. Die Finanzwissenschaft entwickelte damit ihre eigene Replikationskrise – obwohl diese Diagnose auch manche bestreiten.
Eine Replikationskrise bei der Geldanlage ist keine bloße Kränkung der akademischen Eitelkeit, sondern betrifft riesige Geldsummen, die als Folge suboptimal angelegt werden.
Die häufig enttäuschende langfristige Performance von Faktorstrategien hat sicher viele potentielle Gründe: etwa inadäquate Implementierung oder Defizite bei der Transaktionskosten-Berechnung, zeitlich beschränkte oder temporär-regimeabhängige Wirksamkeit. Aber Replikationsprobleme spielen hierbei eben auch eine Rolle, die auf statistische Fallstricke verweisen. Dazu gehören das inzwischen sehr bekannte P-Hacking und diverse, gleichfalls häufig diskutierte „Verzerrungen“ bei Backtests wie vor allem Overfitting. Ein jüngeres und wohl auch subtileres Problem der Faktorbestimmung sind Mängel der Kausalanalyse, die der Finanzmathematiker López de Prado und sein Kollege Vincent Zoonekynd als Factor-Mirage – also „Faktor-Fata-Morgana“ – bezeichnen. Wir gehen im Folgenden auf diese drei Verzerrungsquellen kurz ein.

Der Mathematiker Sir Ronald Aylmer Fisher (1890-1962), der als Universalgelehrter und einer der Begründer der modernen Statistik gilt. Auf ihn geht auch der p-Wert zurück.
Der Trick mit dem Scheunentor: p-hacking Im Jahr 1925 führte der Statistiker Ronald Aylmer Fisher den p-Wert ein, um relevante Ergebnisse besser identifizieren und von bloßen „Störgeräuschen“ unterscheiden zu können. Mit der Zeit wurde der ursprünglich als ein Hilfsinstrument neben anderen intendierte p-Wert in der Statistik immer bedeutsamer. Dogmatisierung, unterschiedliche Interpretationen und offenbar auch Lehrbuchdarstellungen, die nicht im Sinne des Erfinders waren, machten den p-Wert zu einem schillernden Konstrukt, zu einer Art Fetisch der Teststatistik.
Was besagt der p-Test? Man möchte die „Hypothese“, dass der Momentum-Faktor einen bestimmten Effekt auf die Rendite hat, testen. Beim p-Test geht man einen Umweg über das Gegenteil und unterstellt zunächst, dass der Momentum-Faktor keinen (null) Effekt auf die Rendite hat. Das ist die sogenannte Null-Hypothese. Der p-Wert besagt nun: Unter der Bedingung, dass die Nullhypothese zutrifft, ist die Wahrscheinlichkeit, dass der Momentum-Faktor einen mindestens so extremen Effekt erzielt wie beobachtet, gleich p. Man bestimmt dann ein Signifikanzniveau Alpha, gängig waren lange z.B. 0,05 oder 0,01; liegt der p-Wert darunter oder ist gleich, gilt das gefundene Ergebnis als signifikant, liegt er darüber, nicht.
Fachzeitschriften neigten lange dazu, nur Studienergebnisse zu veröffentlichen, die hohe Signifikanz (d.h. tiefe p-Werte) hatten und Studien mit nichtsignifikanten Ergebnissen abzulehnen. Das förderte die Neigung, Ergebnisse mit ausreichend niedrigen p-Werten abzuliefern. Und damit waren Tür und Tor geöffnet für selektives Vorgehen auf künstlich-willentlichem Weg, um die erwünschten p-Werte zu erzielen.
Um P-Hacking bildlich sich vorzustellen, wird häufig ein schlechter Schütze bemüht, der auf ein Scheunentor schießt. Mit der Zeit ergeben sich Stellen mit dichteren Treffermustern. Um eines zieht er einen Kreis und sagt, das sei die Schießscheibe. Die vielen anderen Löcher im Scheunentor spachtelt er zu und überstreicht sie vor der Präsentation.
Bei den vielen Varianten des P-Hackings handelt es sich um unsachgemäßen selektiven Umgang mit Variablen, statistischen Verfahren oder Daten, indem signifikante Ergebnisse präsentiert und nichtsignifikante weggelassen werden.
Ein Beispiel für p-Hacking mit Variablen ist, dass man tausende Korrelationen durchprobiert und nur die signifikantesten veröffentlicht. Ein anderes das Ausprobieren verschiedener statistischer Ansätze, um nur den mit dem besten p-Wert zu veröffentlichten. Schließlich kann auch per Datenselektion P-Hacking betreiben.
Ein Vorteil von Statistik ist, dass man sie auf Statistik (-präsentation) anwenden kann: p-Hacking erzeugt typische Muster in der Verteilung der p-Werte und kann darüber identifiziert werden.
Um dem entgegenzuwirken, wird, auch bei Fachzeitschriften, zunehmend die Veröffentlichung aller Studiendaten verlangt. Teils werden heute deutlich tiefere p-Werte gefordert, in der Regel im Rahmen der t-Statistik (t-Wert). Insgesamt hat der p-Wert an Wertigkeit eingebüßt und ist nur ein Geselle unter anderen Gesellen (Out-of-Sample-Tests; Korrekturverfahren für multiples Testen usw.) und Meistern (z.B. Bayessches Schrumpfungsverfahren; eine überzeugende ökonomische Begründung).
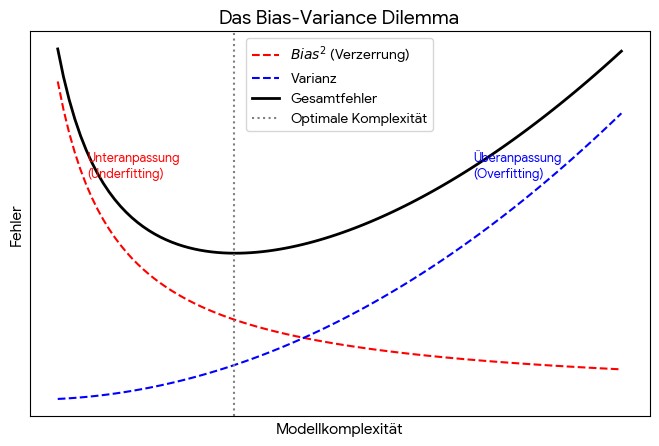
Das Bias-Variance-Dilemma kann durch den Verlauf des Gesamtfehlers in Abhängigkeit von der Modellkomplexität graphisch veranschaulicht werden. Der quadrierte Bias (in der Varianz ist die Quadrierung schon enthalten) nimmt mit der Modellkomplexität ab, die Varianz nimmt hingegen zu. Wo der Gesamtfehler minimal ist, befindet sich das Modelloptimum. Links von diesem Fehlerminimum hat man es mit Underfitting zu tun, rechts davon mit Overfitting.
Scheinbarer Besserwisser: Backtest-Overfitting
Beim Backtesting wird die Performance eines Modells oder einer Strategie anhand von Simulationen auf Basis historischer Daten ermittelt. Das ist zwar sehr nützlich, aber mit etlichen Verzerrungsrisiken verbunden. Zu den bekanntesten gehört der Survivorship Bias, der Look-Ahead Bias oder das Inception-Point-Risiko. Im Kontext des Factor Investings wird insbesondere das Backtest-Overfitting diskutiert. Das Problem kann mit Hilfe eines Bias-Variance-Ansatzes modelliert werden. Bei Überanpassung ist ein Faktor-Modell sehr gut an die zugrunde gelegten Daten der Vergangenheit angepasst; entsprechend gering ist die Modell-Verzerrung (geringer Bias) und entsprechend gut kann dann auch die Performance ausfallen. Der Nachteil: die Varianz der Renditeprognose für die Zukunft oder andere Samples ist sehr groß: Entsprechend enttäuschend ist oft die Performance im Vergleich zu den Ergebnissen des Backtests. Das Risiko von Backtest-Overfitting im Finanzbereich ist aufgrund des Einsatzes von immer höherer Rechenleistung gestiegen, die es erlaubt, eine Vielzahl von Parametervarianten durchzuprobieren, um „optimale“ Strategien für Veröffentlichung oder Markteinführung zu finden. Insofern ist Backtest-Overfitting mit dem P-Hacking verwandt.
Um Backtest-Overfitting zu vermeiden, werden verschiedene Verfahren verwendet, auf die wir hier nicht näher eingehen können, wie Deflated Sharpe Ratio (DSR), Bonferroni-Korrektur, diverse fortgeschrittene Validierungsmethoden und Stabilitäts- bzw. Sensitivitätsanalysen.
Renditen: Kausalität gefragt
Der Finanzmarktstatistiker Marcos López de Prado (der die eben erwähnte DSR entwickelte), moniert zusammen mit Vincent Zoonekynd in einem kürzlich veröffentlichten „Primer“ (Link am Schluss dieses Artikels), dass die zünftige Faktoranalyse das Kausalitätsproblem nur selten fokussiere. In der Regel werden in einem zweitstufigen Verfahren (Zeitreihe für Faktorladungen, darauf aufbauend Querschnitt für Faktorprämien) Regressionsmodelle spezifiziert. Dabei stehe die Maximierung der statistischen Aussagekraft im Vordergrund, während kausale Überlegungen vernachlässigt würden. Jedoch seien Investitionsentscheidungen ihrem Wesen nach kausal, da sie eine Ursache-Wirkungs-Zuordnung von Risikofaktoren zu Renditen implizierten. Das Problem sei jedoch, dass die vorherrschenden Assoziationsverfahren anfällig für Kausal-Verzerrungen seien. Ein Faktor-Modell könne frei von p-Hacking und Backtest-Overfitting sein, aber dennoch kausalanalytisch falsch spezifiziert sein. Durch Anwendung verfügbarer und z.B. in der Medizin bereits gängiger Verfahren könnten diese Verzerrungen entdeckt und beseitigt werden.
„Factor-Mirage“
Unter Factor-Mirage – also Faktor-Fata-Morgana – subsumieren de Prado und Zoonekynd kausal fehlerhafte Modellspezifikationen, von denen sie zwei (von eigentlich 3 dieser Kategorie) ansprechen: (1) Confounder-Bias (Störfaktor-Verzerrung) und 2) Collider-Bias (Selektions-Verzerrung). In beiden Fällen handelt es sich um falsche Kausalitätsstrukturen, wodurch die Korrelationen und auch Erwartungen für Renditen bzw. Risiken verfälscht werden. Beim Confounder-Bias entsteht eine Verzerrung der Korrelation durch eine fehlende Variable, beim Collider-Bias durch eine „schädliche“ Variable in der Regressionsgleichung. Der Confounder-Bias wird durch Einbezug der ursächlichen Variable aufgelöst, beim Collider-Bias erfolgt die Entzerrung durch Rauswurf des Schein-Faktors.
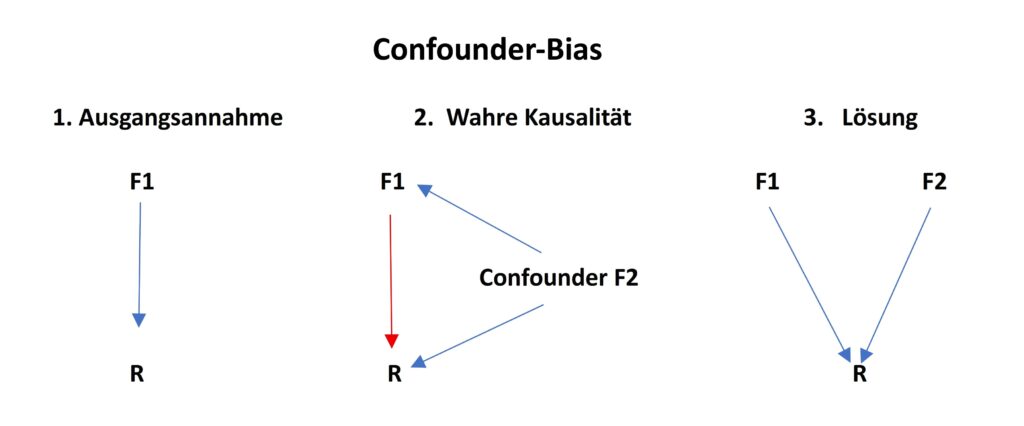
Die Ausgangsannahme (Punkt1) ist, dass ein Faktor F1 die Rendite R beeinflusst. Nun zeigt die Kausalanalyse (Punkt 2), dass ein ignorierter Faktor F2 sowohl F1 als auch R beeinflusst. Im Ausgangsmodell wurde somit die Wirkung Faktors F1 auf R verzerrt berechnet (rote Wirkungslinie). Die Entzerrung (Punkt 3) besteht darin, den Confounder F2 gleichfalls in die Gleichung einzubeziehen (zu „kontrollieren“), um die Kausalitäten korrekt abzubilden.
Confounder-Bias
Ein Confounder ist eine Variable, die kausal mindestens zwei andere Variablen beeinflusst. Der Confounder-Bias entsteht, wenn ein im Modell nichtberücksichtigter Faktor auf zwei Variablen des Regressionsmodells einwirkt. De Prado und Zoonekynd geben hierfür ein Beispiel: Im Ausgangsmodell beeinflusse das Buchwert-Marktwert-Verhältnis (unabhängige Variable) die Rendite (abhängige Variable). Der Verschuldungsgrad (Leverage) werde hingegen nicht berücksichtigt. Bei kausaler Analyse zeige sich aber, dass dieser sowohl das Buchwert-Marktwert-Verhältnis als auch die Rendite beeinflusse. Wegen dieser Nichtberücksichtigung eines Confounders führt das Ausgangsmodell zu einer Verzerrung. Um diesen Bias aufzulösen, muss der Confounder im Regressionsmodell enthalten sein (bzw. kontrolliert werden).
Collider-Bias
Ein Collider ist eine Variable, die kausal von mindestens zwei anderen Variablen abhängig ist. Das Faktor-Beispiel von de Prado und Zoonekynd lautet: Der Qualitätsfaktor werde sowohl vom Buchwert-Marktwert-Verhältnis als auch von der Rendite beeinflusst. Verwendet man nun in der Regressionsgleichung Qualität als Kontrollvariable, dann baut man damit einen Collider ein, der zu einer Verzerrung der geschätzten Koeffizienten und möglicherweise zu falschen Vorzeichen führt: Anleger kaufen dann statt zu verkaufen und umgekehrt. Darüber hinaus lässt sich der ermittelte nichtkausale Zusammenhang nicht monetarisieren. Die Standardvorgehensweise für Faktormodellierung sei gegenüber einem solchen Collider-Bias besonders anfällig, da er in diesem Rahmen nicht entdeckt werden könne und der Collider zudem den Standardfehler reduziere. Eine kausal adäquate Entzerrung erfolgt durch Entfernung des Colliders, im Beispiel also der Qualität, aus der Gleichung.
Zur Identifizierung eines Colliders empfehlen die Autoren Graphenmodelle, die via Kausalnetzwerke Vorfahren und Nachkommen differenzieren. Zur Vermeidung eines Collider-Bias sollte z.B. ein Investor nur die kausalen Vorfahren eines Faktors, in den er investieren möchte, berücksichtigen, nicht jedoch seine Nachkommen. Interessierte vertiefen dies am besten in der Studie (Link am Schluss) selber.
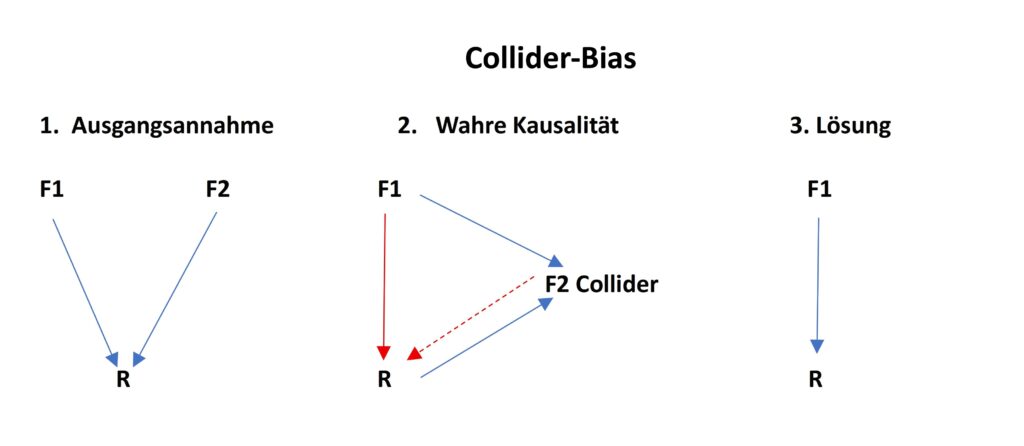
Die Ausgangsannahme (Punkt1) ist, dass Faktor F1 und Faktor F2 die Rendite R beeinflussen. Die korrekte Kausalanalyse (Punkt 2) zeigt nun aber, dass Faktor F2 sowohl von F1 wie auch von R beeinflusst wird. Die Wirkung des Faktors F1 auf R wurde also nicht korrekt ermittelt (roter Pfeil). Und die Wirkung der Ursache F2 (rot gestrichelter Pfeil) ist nur eine Scheinkausalität, die Kausalität geht tatsächlich in die andere Richtung. Die Entzerrung (Punkt 3) besteht in diesem Fall darin, den Collider F2 aus der Gleichung zu streichen.
Schluss
Wer den Faktor-Zoo besucht in der Absicht, in den einen oder anderen Zoobewohner zu investieren, sollte sich unbedingt auch im Gehege für statistische Fabelwesen umschauen. Die Probleme des P-Hacking und des Backtest-Overfitting und mögliche Lösungen hierfür sind im Finanzbereich erkannt und weithin diskutiert worden. Das Kausalitäts-Problem scheint indessen noch der Popularisierung unter Finanz-Praktikern zu harren. Dieser Aufgabe haben sich Marcos López de Prado und Vincent Zoonekynd mit der Schrift „Causality and Factor Investing: A Primer“ gestellt. Darin enthalten ist eine kurze Exposition des Problems und seiner Lösungen plus „Best Practices for Professionals and Asset Owners“ nebst einem weiterführenden Literaturverzeichnis für die Vertiefung.
Link zur Studie: „Causality and Factor Investing: A Primer“